Hoy el webinar que vamos a hacer va a ser relacionado con temas de continuidad de negocio, con temas de infraestructura.
Me presento, Rubén Cuesta, soy el responsable de preventa en Encora y voy a ser quien os dé el webinar de hoy.
Continuidad de negocio
Continuidad de negocio
Continuidad de negocio
Continuidad de negocio
Continuidad de negocio
Continuidad de negocio
Continuidad de negocio
Continuidad de negocio
Continuidad de negocio
Continuidad de negocio
Continuidad de negocio
Continuidad de negocio
Continuidad de negocio
Continuidad de negocio
Continuidad de negocio
Continuidad de negocio
Continuidad de negocio
Continuidad de negocio
Continuidad de negocio
Continuidad de negocio
Continuidad de negocio
Continuidad de negocio
Continuidad de negocio
Continuidad de negocio
Continuidad de negocio
Continuidad de negocio
Continuidad de negocio
Continuidad de negocio
00:23
Índice del Webinar La importancia de la continuidad de negocio
- Conceptos. El índice un poco de lo que vamos a comentar, pues van a ser un repaso de conceptos que la mayoría ya conoceréis relacionados con infraestructura.
- ¿Cuánto dinero nos cuesta una parada no planificada? Vamos a hacer un ejemplo práctico de cuánto nos cuesta una parada que no hayamos planificado en nuestra empresa.
- Continuidad de negocio. Vamos a comentar opciones de continuidad de negocio. Os voy a comentar, cómo Encora, qué es lo que os podemos ofrecer a las empresas.
- Impulsores de un proyecto de continuidad. Y luego vamos a repasar en un último punto, pues quiénes dentro de la organización tienen que ser los impulsores en un proyecto de continuidad de negocio.
Conceptos en la Continuidad de negocio
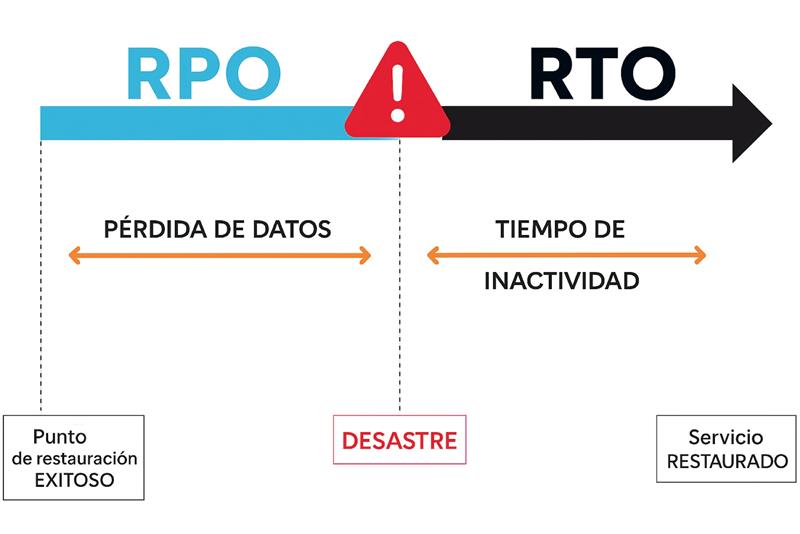
RPO y RTO
Vamos a empezar con dos conceptos que normalmente se oye hablar mucho de ellos, pero igual no tenemos super claro a qué se refieren, que son los conceptos de RPO y RTO.
01:08
Imaginad que tenemos un desastre en un momento dado. Hoy, por ejemplo, son las once de la mañana. Pues hoy a las once tenemos un problema.
Un desastre, algo no está funcionando correctamente y nuestros sistemas no están operativos.
RPO
El RPO, que significa Recovery Point Objective, lo que nos da es una medida del tiempo que podemos perder de datos. Es decir, si nosotros tenemos una estrategia de continuidad de negocio en el que estamos haciendo backup o snapshot o la tecnología que sea cada hora, pongamos, pues si nosotros tenemos un desastre hoy a las once, tendremos que volver atrás en el tiempo a las diez de la mañana.
Esa hora es la pérdida de datos desde la última vez que hemos hecho, pues eso, un backup, un snapshot a nivel de cabina, algún tipo de protección.
Si nos vamos a un escenario más tradicional de que hacemos un backup una vez al día, por ejemplo, para las máquinas virtuales normales, pues si ese backup se hace a las diez de la noche, si tenemos que volver desde hoy, que son las once de la mañana, hasta ayer a las diez de la noche, pues podemos perder trece horas.
Depende un poco de cómo sea nuestra empresa, si trabaja a turnos, 24/7, si solo trabaja en horario de oficina, vamos a perder más o menos datos en función de cuánto hayan escrito, cuánto hayan consultado, modificado nuestros usuarios desde el punto anterior al que nos tengamos que ir.
Por eso ponemos ahí que el RPO está relacionado con los puntos de restauración y la periodicidad con la que hacemos backup o snapshot. Porque tiene que ver cuánto atrás en el tiempo tenemos que ir para poder volver a poner nuestros sistemas en producción.
RTO
El RTO es un concepto que va también en el tiempo, pero hacia adelante. Es Recovery time objective, que es el objetivo de tiempo para poder recuperar el servicio, para poder restaurar nuestros sistemas y que vuelvan a estar operativos.
Pues si hoy a las once, igualmente hemos tenido el problema y tardamos treinta minutos en ejecutar un procedimiento para poder recuperar nuestros sistemas y que nuestros usuarios vuelvan a estar trabajando, pues nuestro RTO será de treinta minutos. Es un tiempo que puede ser muy variable en función de cuál haya sido el escenario de desastre que hayamos tenido.
Pues no será lo mismo un escenario de un ransomware o que se nos haya ido la corriente eléctrica en el CPD y las baterías de nuestros AI, pues hayan aguantado x minutos. A lo mejor no tenemos un generador, a lo mejor, se ha caído la cabina, pero no por un tema de corriente eléctrica, sino que he tenido un fallo hardware, etcétera.
El RTO mide cuánto tiempo tardamos, sea lo que haya pasado, en volver a tener nuestros sistemas operativos.
04:17
Alta disponibilidad
Objetivo: sin puntos únicos de fallo
Cuando hablamos de contingencia o continuidad de negocio, siempre hablamos de un concepto que es la alta disponibilidad. Con la alta disponibilidad lo que buscamos, nuestro objetivo es no tener puntos únicos de fallo.
Redundancia en todos los niveles:
Es decir, que tengamos redundancia, que tengamos alta disponibilidad en todos nuestros sistemas.
- Alimentación eléctrica
Los servidores normalmente tienen doble fuente de alimentación. Cada una de esas fuentes de alimentación la deberíamos conectar a una toma, a una PDU, a una regleta, a lo que tengamos en nuestro data center, pero que sea independiente, que vaya a un SAI independiente, que vaya a un cuadro eléctrico que tenga un diferencial y un magneto térmico diferente de una toma de otra, para así de verdad estar ofreciendo una alimentación eléctrica redundante.
- Conectividad de red
Deberíamos tener un stack de switches Ethernet, un stack de switches Fiber Channel también, diferente para que no dependamos de un único elemento. Imaginad, tenemos un servidor con dos puertos de red. Si esos dos puertos de red van conectados al mismo switch, en caso de que ese switch tenga algún problema, se caiga, se reinicie, solo tenga una alimentación eléctrica y esa fase, pues se nos vaya, pues los dos puertos de nuestro servidor se van a quedar sin conectividad.
Lo lógico es conectar cada uno de esos dos puertos a un switch diferente que esté estacado, que haya una agregación entre esos dos puertos y, de esa forma, seamos capaces de soportar la caída de lo que nos haya pasado con el switch.
- Servidores
De forma idéntica con los servidores. Este a lo mejor es un concepto que lo tenemos mucho más claro.
No podemos depender de un único servidor físico por servicio. Hace años, cuando teníamos servidores sin virtualización, entornos físicos puros, y hoy en día seguimos teniendo entornos con servidores físicos, tenemos que buscar una forma de que un único servicio no dependa de un punto único de fallo, de un único servidor que ejecuta ese servicio.
(poner diapositiva con gráfico)
Por eso, por ejemplo, arriba a la derecha ponemos un servicio de un Datacenter con un balanceador de carga. Imaginad que esos servidores son físicos, que ejecutan esos cuatro servidores son para servir la misma aplicación y tenemos un balanceador de carga por encima para que si un servidor falla, pues los otros tres asumen la carga.
Los usuarios que estuvieran conectados al servicio que tengamos en ese servidor que ha fallado, pues se redistribuye la carga y vuelven a conectarse a los otros tres servidores.
- Almacenamiento
Exactamente igual que hacemos en servidores, lo hacemos también en almacenamiento. Pues sea la topología de almacenamiento que tengamos, sea un entorno tradicional con servidores y cabinas o sea un entorno hiperconvergente en el que el almacenamiento está dentro de cada servidor y luego hay un pool para poder distribuir ese almacenamiento interno entre todos los servidores, pues debemos tener una forma de redundancia.
Si tenemos un servidor o una cabina con doble controladora, que es lo habitual, pues ya no tendremos un punto único de fallo en cuanto a que sea una única controladora. Ya tenemos dos. Si una controladora falla, pues la otra asume la carga. Si tenemos a dos cabinas de almacenamiento en el mismo o en diferentes Datacenters, podemos asumir una tolerancia mayor.
(poner diapositiva con gráfico)
La imagen del centro es una estructura más de un datacenter grande en el que tenemos una salida Ethernet con un router más de edge de frontera, unos routers de acceso y luego unos balanceadores de carga y switches. Switches a nivel de core, nivel uno, switches a nivel de distribución, nivel dos, y los switches top of the rack, que son los switches de acceso a los que van conectados, pues todo lo que tengamos dentro de cada uno de los racks.
Pueden ser servidores, puede ser cabinas de almacenamiento, puede ser firewalls, lo que tengamos ahí. Aquí vemos un poco esa estructura de cómo todo está arrendado para no tener puntos únicos de fallo. Me diréis que el router de frontera, por ejemplo, ahí sí que está representado como un único elemento, pero se supone que eso estaría también redundado.
08:58
Arquitectura activo – activo
Una vez que hemos hablado de alta disponibilidad, vamos a comentar dos arquitecturas muy habituales. Una arquitectura activo-activo y una activo-pasivo.
Vamos a empezar por la activo-activo. ¿Qué es lo que buscamos? ¿Cuál es el objetivo que queremos conseguir con una arquitectura activo-activo?
- Objetivo: mayor rendimiento y disponibilidad
Ofrecer una mayor disponibilidad y un mayor rendimiento. Disponibilidad la tenemos clara. Cuando estamos hablando de que queremos alta disponibilidad, pues lo que buscamos, lo que primamos, es que nuestro servicio siempre esté disponible. ¿Y el rendimiento por qué? Porque cuando tenemos una arquitectura activo-activo, todos los elementos están contribuyendo, todos los servidores están activos.
- Todos los servidores contribuyen, sin que ninguno esté pasivo.
No hay nada que esté en espera, pasivo, esperando a que otro componente falle.
(diapositiva con gráfica)
Por lo tanto, ahí, por ejemplo, tenemos una, una gráfica en la que hay cuatro servidores, pues esos cuatro servidores todos están ofreciendo servicio y no hay ninguno que esté parado. Por tanto, podemos ofrecer más rendimiento porque estamos aprovechando el uso de CPU, de RAM, de esos cuatro servidores.
- Todos los caminos al almacenamiento están activos y en uso
A la vez, en cuanto a la topología de comunicaciones, bueno, en esta imagen no se ve muy bien, parece como que solo los servidores de abajo son los que están conectados a la cabina. Bueno, al final es por esta gráfica, pero la idea es que los cuatro servidores tengan conectividad de forma simultánea y activa a las dos cabinas, de tal forma que cada servidor vea caminos de una cabina y caminos de la otra cabina, todos ellos activos.
- En caso de caída de un servidor, la contingencia es automática sin intervención manual.
En caso de que un servidor se caiga o una cabina o un camino se caiga, pues al final tenemos otros caminos activos, tenemos otra cabina activa, tenemos otros servidores activos, de tal forma que es algo automático la contingencia. No tenemos que hacer nada para que ese servicio siga prestándose a nuestros usuarios.
Es el objetivo que queremos con una arquitectura activo-activo.
10:56
Conceptos: Arquitectura activo – activo
Objetivo: mayor consistencia
Si ahora pasamos a una activo-pasivo, que viene un poco más de entornos del pasado, el típico clúster de dos nodos bien sea de Windows, bien sea de Linux, lo que queramos ver, lo que estamos buscando aquí es una mayor consistencia. No estamos buscando tanto una disponibilidad exquisita, sino que estamos buscando que haya una consistencia en cuanto a los datos.
(diapositiva con gráfico)
- La mitad de los servidores contribuyen, y la otra mitad queda a la espera.
En este ejemplo tenemos ahí dos CPDs. Un CPD está activo y el otro CPD está pasivo. Con lo cual solo la mitad de los servidores está contribuyendo a ofrecer servicio. Los otros, la otra mitad, se queda en espera, con lo cual no estamos haciendo un uso tan eficiente de los recursos, de la CPU, de la memoria, porque la mitad de los servidores está trabajando y la otra está en espera.
- Rendimiento inferior, hardware infrautilizado y sobre aprovisionado
Por tanto, tenemos el hardware infrautilizado y estamos sobre aprovisionando a la hora de comprar. Tenemos que comprar el doble de servidores para ofrecer el mismo servicio.
- En caso de caída de un entorno la contingencia puede ser automática o manual con intervención humana.
En este caso si se cae uno de los entornos, la contingencia, en función de lo que haya pasado, puede que sea automática o puede que no, que tengamos nosotros que intervenir para poder poner en marcha esa contingencia de forma manual.
12.19
Coste de una parada no planificada (ejemplo)
Aquí os quería poner un ejemplo de cuál sería el coste que supone para una empresa una parada no planificada, un desastre.
Imaginad este escenario. Tenemos una empresa con trescientos empleados y vamos a hacer una media entre empleados con un salario más bajo, otros con un salario más alto.
Imaginad que ponemos, por ejemplo, pues un salario bruto medio anual de treinta mil euros. Tenemos que incluir los costes para la empresa de la Seguridad Social, beneficios sociales, etcétera. Pongamos que tenemos cuarenta mil quinientos euros por año por empleado. Ahora, tenemos una parada no planificada.
En función del tiempo que hemos tardado en poder volver a tener el servicio activo.
¿Cuál es el impacto económico de tener a 300 empleados sin poder trabajar durante X horas?
(diapositiva con gráfico)
Os he preparado aquí una tabla y hablaríamos de estos importes. Si el RTO, si el tiempo que tardamos en poner activo otra vez la empresa es una hora, pues esos trescientos empleados supondrían un impacto económico para la empresa de seis mil novecientos euros.
No parece demasiado, pero imaginad que ha sido un problema más grave, que no conseguimos en una hora poner en funcionamiento los sistemas y que seguimos teniendo los trescientos empleados mano sobre mano, sin saber qué hacer, sin poder trabajar. Pues si hablamos de cuatro horas de parada, ya el importe ya empieza a subir a algo considerable, veintisiete mil seiscientos euros.
Si la parada es mayor todavía, ocho horas, cincuenta y cinco mil doscientos euros. Imaginad que tenemos un problema hardware importante y que entre que abrimos el caso con el fabricante, nos dicen que nos dan un soporte 24/7 con tiempo de respuesta cuatro horas.
Pero resulta que entre que hacemos un análisis previo, obtenemos los logs, se los mandamos, lo empiezan a analizar, descubren que sí, que hay una pieza hardware que tiene que cambiarse, que no está redundada y que nos la envían, pues al final imaginad que tenemos a veinticuatro horas paradas, un día, solo un día la empresa parada, pues eso ya supone ciento sesenta y cinco mil seiscientos euros de impacto económico para la empresa por tener a esos trescientos trabajadores sin poder trabajar.
Aparte del problema de imagen, reputación, marca, etcétera. Todo esto ya es impacto económico de que los trabajadores no pueden trabajar. Aquí ya estamos hablando de un importe muy considerable. Sí, seguramente por lo que nos cuesta una única parada de ocho horas o veinticuatro horas, podemos acometer un proyecto para poder ofrecer alta disponibilidad a nuestra empresa.
15:15
Continuidad de negocio
Continuidad de negocio ¿Qué debemos tener en mente?
Vamos a pasar ahora a la fase de continuidad de negocio. ¿Qué es lo que debemos tener en mente para poder hacer un plan de continuidad de negocio? Pues lo primero es saber de qué partimos. Deberíamos hacer un análisis de la situación actual, saber cómo es nuestra infraestructura, cómo de resiliente es, y para ello necesitamos una auditoría. Una auditoría inicial que va a trasladar después como entregable un plan de continuidad de negocio.
- Auditoria inicial ¿El número de servidores está bien dimensionado? ¿Se necesitan más? ¿Redundancia N+1 oN+N?
¿Qué es lo que haríamos en esa auditoría? Pues revisaríamos, oye, el número de servidores, lo tenemos bien dimensionado, el número de servidores físicos ¿Necesitamos más? ¿Redundancia N + 1 o N + N?
Cuando hablamos de redundancia N + 1 es que si nosotros para poder ofrecer el servicio necesitamos tres servidores y si uno de esos tres se nos cae, ya no podemos ofrecer, no podemos ejecutar todas las máquinas virtuales, necesitamos al menos un servidor adicional para poder cubrir que uno de los otros tres falle.
Eso se llama redundancia N + 1. Si necesitamos tres, pues como mínimo tendremos que provisionar cuatro. Ya no solo para planes de prevenir un desastre, sino porque vamos a tener que hacer operaciones de mantenimiento, tendremos que parchear el sistema operativo de esos servidores, tendremos que instalar actualizaciones de firmware, tendremos que instalar nuevas versiones del software, del hipervisor, de lo que sea. Necesitamos de vez en cuando poner uno de ellos, de forma rotativa, en modo mantenimiento.
La redundancia N + N sería el caso de tener una topología activo- pasivo. Imagina que nosotros necesitamos tres servidores para poder dar servicio a la empresa, pues, N sería tres. Entonces, tendríamos tres servidores activos y otros tres servidores pasivos esperando a que pueda haber una contingencia con esos tres servidores, con el CPD donde se alojan. Tenemos que poner tres servidores en un datacenter, tres servidores en el otro datacenter o en un rack y en otro rack. Pero esa es la redundancia que tenemos que pensar.
- ¿Se dispone de un segundo Datacenter? ¿Es necesario?
Hablando de datacenters, ¿tenemos un segundo data center o no? ¿O solo tenemos uno? Si solo tenemos uno, volvemos al punto que estábamos comentando de punto único de fallo. ¿Qué pasa si ese datacenter tiene un problema, ya sea eléctrico, ya sea de una fuga de agua, ya sea de conexión a Internet? lo que sea, ese datacenter, si no está operativo, tenemos a todos nuestros empleados sin poder trabajar.
¿Necesitamos un segundo data center para poder tener un plan de continuidad? Pues sería uno de los puntos que evaluaríamos en esa auditoría.
Imaginad, por ejemplo, que tenemos una arquitectura tradicional de servidores y cabina. ¿Tenemos una segunda cabina? ¿Qué pasa si nuestra cabina se cae y no está operativa?
Podéis decirme: «Bueno, pues es que es, la cabina la tenemos con doble fuente de alimentación y doble controladora. Muy malo será que las dos controladoras dejen de funcionar a la vez». Bueno, pues sí, seguramente es poco probable que las dos controladoras fallen a la vez, pero sí que es bastante fácil que pueda pasar que a lo mejor tengamos un problema eléctrico en ese datacenter.
Imaginad, estamos en el típico polígono industrial, tenemos, problemas de alimentación eléctrica, de vez en cuando se va, o somos una gran industria y estamos regulados por red eléctrica y de vez en cuando nos tienen que cortar corriente para poder proveer al pequeño consumidor. Pues si solo tenemos una alimentación eléctrica, por mucho que tengamos dos SAIs, si no tenemos un generador, pues podemos sufrir.
- ¿Se dispone de una segunda cabina? ¿O es un entorno hiperconvergente y crecemos en base a nodos?
Si tenemos un segundo datacenter geográficamente un poco, distante y tenemos una segunda cabina, vamos a poder seguir ofreciendo conectividad y servicio hacia nuestros usuarios.
Otro escenario, un escenario de entorno hiperconvergente. Un entorno hiperconvergente es en el que crecemos en base al número de nodos y que tenemos cada nodo, cada servidor físico tiene potencia de CPU, de RAM y almacenamiento.
Almacenamiento que se comparte con todo el resto de nodos. Pues si es un entorno hiperconvergente no tenemos una segunda cabina, estaremos más en el primer punto de ¿Cuántos servidores tenemos?
¿Qué redundancia tenemos? ¿Redundancia N +1 o tenemos un N +N?. Pues tenemos que analizar la carga, tenemos que medir durante unos días el entorno para ver cómo responde, porque al final muchas veces estamos acostumbrados a decir:
«Bueno, yo veo el instante ahora de cómo está de carga de CPU, de RAM mis servidores y veo que uno está al treinta por ciento, otro al treinta por ciento, otro está al diez por ciento, pues estoy bien».
Pero a lo mejor hay momentos del día en el que ese treinta por ciento se convierte en un cincuenta y el diez por ciento se convierte en un veinticinco. Y a lo mejor hay picos en los que con tres servidores no somos capaces de ofrecer que uno de ellos se caiga y los otros dos aguanten todas las máquinas. Pues tenemos que evaluarlo.
- ¿La electrónica de red y salidas a Internet están redundadas?
Por otro lado, conectividad de red, electrónica de red. ¿La tenemos redundada? ¿Tenemos doble electrónica en stack para que podamos…? Los switches, no es tan habitual, pero también hay que parchearlos, hay que instalarles nuevas versiones. Se pueden caer, puede tener un problema eléctrico y se puede reiniciar un switch. Si no tenemos los servidores y las cabinas conectados a switches diferentes, pues podemos tener un impacto.
Salidas a Internet, exactamente lo mismo. Si tenemos un único proveedor de Internet, porque por lo que sea, en nuestras oficinas, en nuestro polígono, en nuestra industria, solo tenemos un proveedor de fibra, tendremos que buscar soluciones alternativas: 4G, 5G, conexión de satélite, etcétera. Pero tenemos que tener contemplado que nuestro proveedor de Internet nos puede dejar tirados en algún momento.
- ¿Solución de backup con inmutabilidad real? ¿Planes de continuidad probados?
Por último, y no menos importante, solución de backup. Solución de continuidad de negocio, hablamos de ¿Nuestra solución de copia de seguridad tiene inmutabilidad real? ¿Es resistente a ataques de ransomware? ¿Tenemos un plan de continuidad descrito con un paso a paso de qué es lo que tenemos que hacer cuando tengamos un desastre?
Hay diferentes casuísticas de desastre, tenemos que tener bien documentado por cada uno de los escenarios de desastre qué tenemos que hacer, porque en el momento del desastre normalmente no tenemos la cabeza como para poder pensar de forma clara.Tenemos a nuestros jefes que están encima de nosotros para: «¿Falta mucho para poder tener otra vez el entorno operativo?»
Tenemos presión, con lo cual hay que tener un plan de continuidad bien descrito y probar, probarlo, porque al final esto es un ciclo de mejora continua y habrá que ver que cuando lo probemos por primera vez, seguramente encontremos algún punto flojo y tengamos que mejorar. Hasta aquí el plan de continuidad de negocio.
22:53
Continuidad de negocio: Datacenters
Vamos a hablar un poco ahora a nivel de data centers. Comentábamos ¿tenemos un segundo datacenter? bueno, pues tenemos que revisar qué necesitamos para que un segundo datacenter nos proporcione de verdad disponibilidad independiente.
Requerimientos de un segundo datacenter:
- Acomedida eléctrica diferenciada
De primeras, necesitamos una acometida eléctrica que sea diferenciada de la primera. ¿Esto cómo es? Depende un poco de dónde está ese segundo datacenter. En escenarios, imaginad que es, pues oye, dentro de las mismas oficinas, separado doscientos metros, porque es un cuarto técnico que tenemos ahí disponible.
La acometida eléctrica es la misma, pues seguramente en ese edificio sí, no tengamos doble acometida eléctrica. Si tenemos, en cambio, un datacenter que está en otra nave, en otro edificio, que está a un kilómetro, a dos kilómetros, a treinta kilómetros, pues seguramente las acometidas eléctricas sí que pueden ser diferenciadas.
En todo caso, si en función de la criticidad de nuestro negocio, podemos hablar con el proveedor de, de suministro eléctrico para ver, pues dónde están los centros de transformación más cercanos y ver si a un datacenter y a otro datacenter puede llegar acometida desde centros de transformación diferentes. Idealmente, podría ser incluso con un proveedor diferente, pero eso ya no está en nuestras manos, eso al final es la disponibilidad que tengamos de los proveedores.
- Conexión a Internet
Necesitamos también de proveedores diferentes. No, normalmente no es una buena idea contratar dos líneas, por ejemplo, de fibra al mismo proveedor, o contratarlas a proveedores diferentes, pero que la última milla, al final el proveedor real que llegue físicamente hasta nuestras instalaciones sea el mismo.
Imaginad que contratamos una fibra de Movistar y otra de Vodafone, pero Vodafone físicamente no llega, Orange tampoco llega y al final tiene que subcontratar a Movistar para poder llegar. Pues al final, si Movistar es el que tiene un problema, tanto la línea principal como la línea de backup nos deja tirados.
Por eso tenemos que ver si tenemos alternativa con conexiones de fibra de diferentes proveedores, sería lo ideal. Si solo nos llega fibra de un proveedor, tenemos que ver alternativas, como eso, como un 4G, un 5G o una conexión de radioenlace o un satélite, etcétera.
- Ubicación on-prem: otro edificio/ nave lo más distante posible.
Hablando de dónde ubicamos ese segundo data center, puede ser on-prem, es decir, en nuestras oficinas, en nuestra nave, etcétera. Idealmente, lo más distante posible uno de otro, para no tener la capacidad de sufrir el mismo desastre, sea lo que sea: un problema de corriente eléctrica, una fuga de agua, una inundación, un terremoto, etcétera.
- Ubicación externa: puede contratarse alojamiento en un proveedor externo, Collocation.
Pero también podemos pensar: «Oye, pues es que no tenemos otra ubicación dentro de nuestras oficinas, dentro de nuestras naves, no hay una segunda ubicación». Y construir una segunda ubicación contando que necesitamos, pues que si un suelo técnico, que si una climatización, una protección contra incendios, cuadros eléctricos, etcétera.
Eso a lo mejor es muy cara la inversión que hay que hacer, pues se puede contratar en un proveedor externo, en un collocation. Es una forma muy ágil de un pago por consumo. Yo, las máquinas que yo meto en ese data center son mías, pago un housing, pero pago simplemente por el espacio que utilizo dentro del rack, por la conectividad que necesito de red y por la potencia eléctrica que esté consumiendo.
- Ubicación cloud público: sin inversión upfront, pago por uso.
Otra alternativa que lleva unos años también en boga es tener un disaster recovery en un cloud público, el que sea: Google, Azure, Amazon, otros. En ese caso, no tenemos que hacer una inversión upfront, no tenemos que comprar nosotros servidores, cabinas, switches, etcétera, y simplemente hacemos un pago por uso.
Esta solución puede estar muy bien porque no tenemos que hacer una inversión por adelantado, pero tenemos que contemplar hacer un estudio de costes muy serio recurrente, mensual, para ver cuánto nos puede costar en el caso de que haya un desastre, esos costes adicionales y sobre todo tener pensado, pues todos los escenarios de lo que pueden fallar.
Es decir, si a mí me falla la conectividad a Internet, no me sirve de nada que el disaster recovery lo tenga en un cloud público, porque si no tengo conexión a Internet no lo voy a poder conectar tampoco a esos servicios que están ofreciéndose desde un cloud público.
Todo hay que, hay que mirarlo, pero eso os podemos ayudar a realizar.
Un segundo Datacenter independiente permite afrontar múltiples escenarios de contingencia:
- Caída de comunicaciones a Internet
Un segundo Datacenter, ¿Qué escenario nos permite ofrecer en cuanto a una contingencia? Pues nos permite que si están geográficamente separados, pues un problema de caída de comunicaciones a Internet, que cada datacenter tenga su propia salida a Internet. Idealmente, que sea de proveedores diferentes.
- Problema de suministro eléctrico
Que si un data center tiene un problema de suministro eléctrico, el otro no lo sufra.
- Fuga de agua o inundación
Que haya fenómenos naturales, una fuga de agua dentro del edificio o que haya una inundación, que haya un terremoto, etcétera.
- Problema con la climatización o PCI
Algo más habitual, que tengamos un problema con la climatización o con la protección contra incendios.
Imaginad que tenemos, pues uno o dos splits de aire acondicionado y de repente fallan. Sabemos que en un Datacenter, en el momento que no tenemos aire acondicionado, los grados empiezan a subir en cuestión de minutos, con lo cual es muy fácil que antes de que nos demos cuenta ya tengamos un problema serio, etcétera. Tenemos que tenerlo también en cuenta.
- Fallos HW: servidor, cabina, electrónica.
Y por supuesto, un segundo Datacenter nos provee de soluciones en cuanto a fallos hardware. Que nos falla un servidor en un Datacenter, pues tenemos servidores en el otro. Que falla una cabina, tenemos otra cabina. Que nos falla electrónica en un Datacenter, pues en el otro también tenemos.
Es al final el mensaje que comentábamos al principio de tenemos que evitar puntos únicos de fallo.
28:56
Continuidad de negocio
Continuidad de negocio: Activo – Activo o Replicación
Y hablando de continuidad de negocio, pasamos a tecnologías como son la activo-activo que comentamos antes o la replicación. Y esto aplica tanto a escenarios de arquitecturas hiperconvergentes como tradicionales.
Tanto en arquitectura hiperconvergente como tradicional se puede diseñar una topología de clúster extendido en el que haya servidores activos en casa Datacenter.
Al final, diseñar una tecnología de un clúster extendido en el que tenemos servidores o nodos en un Datacenter y en el otro, todos ellos activo-activo, es una muy buena práctica, porque estamos ofreciendo una disponibilidad muy superior así a la que tenemos como un activo-pasivo, que tenemos que comprar el doble de hardware, pero la mitad está parada en standby esperando a que la otra falle.La tecnología activo-activo hace un uso mucho más eficiente de los recursos.
Bien sea un almacenamiento compartido mediante hiperconvergencia, o mediante una red SAN es necesaria la replicación de información entre Daracenters.
En este caso, depende un poco cómo sea nuestra arquitectura. Si es una arquitectura tradicional con cabinas, pues tenemos que replicar la información de una cabina a la otra.
Tenemos dos tipos de replicación:
- Replicación síncrona. RPO = 0.
En el que a un servidor del Datacenter A no se le dice que se ha escrito la información hasta que no está escrita realmente en la cabina del datacenter A y en la cabina del datacenter B. Tiene que escribirse entre los, en las dos cabinas para que el servidor reciba el acknowledge, el OK, ya está escrito. Esto, lógicamente, tiene unos requisitos de distancia, latencia de las comunicaciones entre los dos Datacenters. Pero es la replicación idónea para un escenario de activo-activo y tecnología de mayor disponibilidad.
En ese caso, el RPO, el recovery point objective, es el tiempo en el que tenemos que volver atrás para poder tener otra vez el entorno productivo.En caso de que me falle una cabina, la otra cabina en tiempo real está sincronizada, con lo cual el RPO son cero segundos. No tenemos ninguna demora.
- Replicación asíncrona. RPO > 0.
Si en cambio hacemos una replicación asíncrona, el RPO siempre va a ser mayor que cero. Podemos hacer replicación cada cinco minutos, cada quince minutos, cada cinco segundos, lo que sea, pero siempre va a ser mayor que cero.
Con lo cual, parte de la información la perdemos, lo que se escribe en los últimos segundos, minutos, horas, depende con qué periodicidad hagamos la réplica, se puede perder.
Aquí estamos hablando, por ejemplo, del caso de uso de replicar entre cabinas, pero algo muy habitual en España, por ejemplo, es mediante Veeam Backup hacer réplicas de las máquinas virtuales de un Datacenter a otro o de unos host a otros. Pues en función de cada cuánto se ejecuten esos jobs de réplica, cada horas, cada veinticuatro horas, cada cuatro horas, pues ahí tendremos fijado nuestro RPO.
En el caso de un almacenamiento compartido por hiperconvergencia, por nodos, es un escenario también activo-activo, normalmente. En función de la tecnología que utilicemos de hiperconvergencia, sea VSAN, sea Nutanix, sea SimpliVity, lo que sea, pues tenemos unas formas de poder mantener esos nodos con la información actualizada.
32:07
Continuidad de negocio: Backup y Restore.
¿Qué es lo que tiene que incluir una solución moderna de copia de seguridad?
- Inmutabilidad
De entrada, tiene que ser inmutable. Hoy en día ya hemos sufrido, si no lo hemos sufrido en nuestra empresa, lo hemos oído muchísimas veces todos estos últimos años del problema de ataques por ransomware.
Con lo cual tenemos que ser capaces de que nuestro backup tiene que ser inalterable.
Esto se consigue con inmutabilidad, pero inmutabilidad real, efectiva, porque sí que hemos visto casos de clientes que pensaban que tenían múltiples niveles de copia y que algunos eran inmutables y a la hora de la verdad, los ciberdelincuentes han sido capaces de primero borrarles los backups.
Al suceder esto ya no era inmutable, si alguien te puede borrar un backup, no es que te lo altere, que si te lo borra, pues ya no puedes volver a restaurar de ahí. Pues la inmutabilidad de base.
- Seguridad: MFA, múltiples aprobadores, mínimos privilegios.
Luego tenemos que ser capaces de ofrecer seguridad. Pues eso, un múltiple factor de autenticación para poder acceder a los sistemas de copia de seguridad.
Disponer de múltiples aprobadores. Es decir, yo soy el administrador de mi empresa y yo tengo autoridad para poder borrar un backup. Pues no, lo lógico es que haya múltiples aprobadores, que haya dos, tres personas que tengan que dar su OK para que si un ciberdelincuente consigue las credenciales de un administrador, pues que no tenga capacidad completa para poder borrar, alterar, modificar esos backups. Que se necesite la aprobación de varias personas.
Luego, por supuesto, sentido común, utilizar mínimos privilegios a la hora de realizar las actividades, que nuestro usuario del día a día con un usuario con privilegios de administrador y tengamos un usuario específico administrador para tareas que se necesiten, etcétera.
- Air-gap (copias desconectadas).
Copias desconectadas o copias offline. Esto toda la vida se ha hecho mediante cintas LTO, pero hoy en día hay soluciones de backup a disco que se llaman Air Gap, que es que el almacenamiento destino no está disponible todo el tiempo, de tal forma que un ciberdelincuente no sea capaz de poder acceder, aunque no sea capaz de borrarlo porque sean inmutables, pero ni siquiera va a ser capaz de conectarse a ver ese almacenamiento destino.
Va a estar con un vacío de aire, va a estar desconectado y solo se va a conectar ese almacenamiento cuando el software correcto de copia de seguridad va a hacer un backup o cuando necesita hacer un restore.
- Eficiencia en el almacenamiento.
Ya sabemos que cada vez los usuarios consumen más y más espacio de almacenamiento, necesitamos más espacio en las cabinas primarias y, por tanto, a la hora de hacer backups, vamos a necesitar también mayor espacio en nuestros backups.
Con lo cual necesitamos tecnologías como puede ser; compresión, deduplicación, etcétera, para que en nuestros backups tengamos eficiencia y no estemos comprando discos y discos para poder guardar cada vez más y más información.
- Rendimiento tanto en backup como, sobre todo, en restore.
Uno de los puntos más importantes es el del rendimiento. Muchas veces le prestamos atención a cuánto tiempo tarda en hacerse nuestros backups, las copias incrementales, las copias full. Pero mucho más importante que esto es el tiempo que tardamos en hacer una restauración. Y no me refiero a hacer una restauración simplemente de un fichero o de una máquina virtual individual. Eso puede ser más corto, menos tiempo.
Hablo de, en un escenario de contingencia completa, hemos sufrido un problema muy importante, muy severo, de que nos han cifrado, por ejemplo, los hosts de VMware o que hemos tenido un problema de total indisponibilidad de nuestros servidores y tenemos que recuperar todo el almacenamiento. Alguien ha borrado la cabina primaria, por ejemplo.
Pues ¿cuánto tiempo tardamos en restaurar no una máquina virtual, sino las decenas o cientos de máquinas virtuales que tiene nuestra infraestructura? ¿Lo hemos probado alguna vez ese tiempo? ¿Hemos visto si estamos hablando de que lo somos capaces de recuperar en horas o necesitamos días o incluso semanas? depende de la tecnología que tengamos en ese backup.
No es lo mismo hacer un backup y un restore por una interfaz a un gigabyte que hacerlo a diez o a veinticinco gigas, que la tecnología de disco sea más rápida o no, que hayamos utilizado deduplicación y tengamos que rehidratar nuestras copias para poder hacer la restauración. Son puntos que tenemos que tener en cuenta.
- Escalabilidad consistente independientemente del almacenamiento necesario.
Por otro lado, escalabilidad consistente y además independiente del almacenamiento necesario. Es decir si nosotros ahora necesitamos alojar diez teras y de repente viene un nuevo proyecto y necesitamos otros cinco teras adicionales, ¿tenemos que tirar todo lo que tenemos porque nuestro destino de backup y nuestro software no está preparado? ¿O somos capaces de escalar de forma consistente?
Agregamos un nuevo nodo, si estamos hablando de arquitectura tradicional, nodo de scale out o ampliamos almacenamiento en una arquitectura de tipo scale up, etcétera. Tenemos que tenerlo en cuenta.
- Backups consistentes con aplicaciones y bases de datos.
Por otro lado, lógicamente, nuestra solución de copia de seguridad tiene que ser consistente con aplicaciones y bases de datos.
Esto ya lo doy por supuesto en cualquier solución moderna, pero hacemos énfasis en ello y tenemos que comprobarlo, que aunque la tecnología lo permita, que nosotros lo estemos utilizando. Es decir, que si estamos haciendo backup de un SQL Server, de un Oracle, del directorio activo, de lo que sea, que sea aplicación o base de datos, que estemos haciendo un uso de application aware.
- Soporte para múltiples hipervisores, servidores físicos, contenedores, etc.
Y por otro lado, que nuestra solución sea lo más heterogénea posible. Es decir, que soporte múltiples hipervisores, porque hoy en día podemos estar con un hipervisor y pasado mañana podemos optar a cambiar a otro y que no tengamos que cambiar nuestra solución de copia de seguridad, que sea capaz de hacer backup de máquinas virtuales, de servidores físicos, de tecnología de contenedores, etcétera.
Pues todos esos al final son parámetros que tenemos que tener dentro de nuestra tecnología de copia de seguridad.
38:45
¿Cómo os podemos ayudar desde Encora?
Auditorías iniciales.
Os podemos ofrecer esa auditoría inicial para ver cómo está vuestra infraestructura. Poder analizar y poder hacer recomendaciones para poder mejorar la disponibilidad de la infraestructura.
Planes de continuidad de negocio: diseño y ejecución.
Podemos ayudaros o podemos encargarnos de hacer un plan de continuidad de negocio completo, desde la fase de diseño, habiendo partido de la auditoría, hasta la fase de ejecución. Esto es algo que hacemos frecuentemente en clientes. Es decir, pues oye, una vez al año, por lo menos, probamos el plan de continuidad de negocio, lo ejecutamos.
En algunos casos es en fin de semana, en otros casos es en horario laboral, depende del entorno de cada cliente, pero lo ejecutamos, miramos, tomamos tiempos, documentamos, revisamos el procedimiento paso a paso, entrenamos a los administradores del cliente y confirmamos si hay algún punto de mejora para la siguiente ejecución.
Diseño de arquitecturas robustas.
Os podemos ayudar a diseñar arquitecturas robustas. Lo que hemos visto antes, evitar puntos únicos de fallo, tecnología de un único Datacenter, etcétera.
Identificar segunda ubicación idónea de Datacenter.
Podemos ayudaros a buscar cuál es la ubicación ideal en vuestro caso para ese segundo o tercer Datacenter, depende de lo que necesitéis.
Añadir alta disponibilidad a infraestructuras actuales.
Podemos ayudaros a que vuestras infraestructuras sean más altamente disponibles. A lo mejor ahora mismo ya lo son y podemos reforzarlo, podemos darle un paso adicional.
Apoyo legal y técnico para adecuación a normas: ENS, NIS2, DORA.
También podemos ayudaros en el apoyo legal, pero también técnico para adecuación a las normas. Esquema nacional de seguridad, ISO 27001, NIS2, que aplica a muchísimas empresas, DORA, más centrada en entorno de sector financiero y de seguros.
40:39
Kowakia
A lo mejor conocéis desde Encora que tenemos la capacidad de ofreceros ese asesoramiento técnico, pero hay dos novedades que contaros. Ya hemos sacado al mercado nuestra nueva empresa de ciberseguridad, la que será una división de Encora, que se llama Kowakia y es apoyo puro técnico para todos los temas de ciberseguridad.
41:03
Compliance y legal
También tenemos una nueva unidad de negocio dentro de Encora, que es la parte de compliance y legal, donde tenemos a una compañera que es especialista, es abogada, para ayudaros con toda la parte de interpretación, ayuda de descripción de todos los procedimientos técnicos para estas normas que ya son de obligado cumplimiento.
Por ejemplo, NIS2, ya todas las empresas que les aplica, pues tendrían que estar adecuadas a esa norma y si no, pues pueden venir sanciones.
41:37
¿Quién impulsa un proyecto así?
¿Somos nosotros como responsables IT? ¿Es el CIO de la empresa? ¿Tiene que venir del CISO, si tenemos un CISO? ¿O no es tanto la parte IT, sino que tiene que ser negocio?
Por ejemplo, un responsable de mantenimiento en una industria, un responsable de producción en una fábrica. Al final, lo que nosotros decimos es que esta responsabilidad no es tanto del lado IT, sino que tiene que venir más de negocio o de dirección de la empresa.
Son los que tienen que darse cuenta, sobre todo, además, por estas normas que comentábamos antes, NIS2, DORA, si estáis en proceso de adecuarnos a esas normas, lo que dicen las normas es que los responsables legales y penales, al fin de no cumplir esas normas, son los directivos de las empresas, no el responsable de IT, no el administrador de sistemas.
Puede ser un CIO, puede ser el CEO de la empresa. Con lo cual, os podemos apoyar para daros argumentos para trasladar hacia arriba, hacia la dirección de la empresa, que son los que tienen que impulsar este tipo de proyectos.
Si crees que te podemos ayudar en la continuidad de negocio de tu empresa puedes contactarnos fácilmente y hablaremos sin compromiso para orientarte: ¿Hablamos?
Muchas gracias.
